
Nếu microservices là các thành phố, thì Kafka chính là hệ thống đường cao tốc kết nối chúng lại.
Đã làm việc với Kafka nhiều năm, từ những ngày đầu setup cluster 3 broker cho một startup nhỏ, đến việc vận hành hệ thống xử lý hàng triệu events/giây tại production. Bài viết này là tất cả những gì tôi ước mình biết từ ngày đầu tiên.
# kafka là gì?
public class MaxStack {
private Deque<Integer> mainStack;
private Deque<Integer> maxStack;
public MaxStack() {
mainStack = new ArrayDeque<>();
maxStack = new ArrayDeque<>();
}
public void push(int x) {
mainStack.push(x);
if (maxStack.isEmpty()) {
maxStack.push(x);
} else {
int currentMax = Math.max(x, maxStack.peek());
maxStack.push(currentMax);
}
}
public void pop() {
if (!mainStack.isEmpty()) {
mainStack.pop();
maxStack.pop();
}
}
public int top() {
if (mainStack.isEmpty()) {
throw new IllegalStateException("Stack is empty");
}
return mainStack.peek();
}
public int getMax() {
if (maxStack.isEmpty()) {
throw new IllegalStateException("Stack is empty");
}
return maxStack.peek();
}
}Apache Kafka là một distributed event streaming platform. Nghe fancy, nhưng bản chất nó là một hệ thống cho phép bạn:
- Publish (ghi) và Subscribe (đọc) các luồng dữ liệu (events/messages)
- Store dữ liệu đó một cách bền vững và có khả năng chịu lỗi
- Process dữ liệu theo thời gian thực hoặc hồi tố
Hãy nghĩ Kafka như một commit log phân tán — mọi thứ được ghi vào đều immutable, có thứ tự và có thể đọc lại bất cứ lúc nào.
# why not RabbitMQ or Redis Pub/Sub?
Đây là câu hỏi tôi nhận được nhiều nhất. Câu trả lời ngắn gọn:
| Tiêu chí | Kafka | RabbitMQ | Redis Pub/Sub |
|---|---|---|---|
| Throughput | Hàng triệu msg/s | Hàng chục nghìn msg/s | Hàng trăm nghìn msg/s |
| Message Retention | Có (configurable) | Không (consumed = gone) | Không |
| Consumer Groups | Native support | Limited | Không |
| Replay Messages | Có | Không | Không |
| Ordering Guarantee | Per-partition | Per-queue | Không |
| Use case chính | Event streaming, Log aggregation | Task queue, RPC | Real-time notifications |
Rule of thumb: Nếu bạn cần fire-and-forget task queue → RabbitMQ. Nếu bạn cần event log mà nhiều service cùng đọc → Kafka.
# kiến trúc kafka
# broker — Trái tim của Kafka
Broker là một Kafka server instance. Một Kafka cluster thường có nhiều broker (tối thiểu 3 cho production). Mỗi broker:
- Nhận messages từ producers
- Lưu trữ messages trên disk
- Phục vụ messages cho consumers
- Tham gia vào quá trình replication
# topic — kênh dữ liệu
Topic là một logical channel để tổ chức messages. Hãy nghĩ nó như một bảng trong database, hoặc một folder trong file system.
Topic: "order-events"
├── Partition 0: [msg0, msg1, msg4, msg7, ...]
├── Partition 1: [msg2, msg3, msg5, msg8, ...]
└── Partition 2: [msg6, msg9, msg10, ...]
Naming convention tôi hay dùng:
<domain>.<entity>.<action>→payment.order.created- Hoặc đơn giản:
<entity>-events→order-events
# partition — Chìa khóa của Scalability
Đây là concept quan trọng nhất cần hiểu. Mỗi topic được chia thành nhiều partitions, và đây chính là cách Kafka scale horizontally.
Tại sao partition quan trọng?
- Parallelism: Mỗi partition có thể được đọc bởi một consumer riêng biệt
- Ordering: Messages trong cùng một partition được đảm bảo thứ tự (FIFO)
- Distribution: Partitions được phân bố đều trên các brokers
Producer gửi message với key = "user-123"
│
▼
hash("user-123") % num_partitions = partition_id
│
▼
Tất cả events của user-123 luôn vào cùng 1 partition
│
▼
→ Đảm bảo thứ tự xử lý cho từng user
Bao nhiêu partitions là đủ?
Công thức tôi hay dùng:
num_partitions = max(T/P, T/C)
Trong đó:
- T = target throughput (msg/s)
- P = throughput mỗi producer có thể đạt trên 1 partition
- C = throughput mỗi consumer có thể đạt trên 1 partition
Thực tế: bắt đầu với 6-12 partitions cho hầu hết use cases. Scale up khi cần (nhưng không thể scale down).
# offset — bookmark của consumer
Mỗi message trong một partition có một offset — một số nguyên tăng dần, bắt đầu từ 0. Offset chính là cách consumer biết mình đã đọc đến đâu.
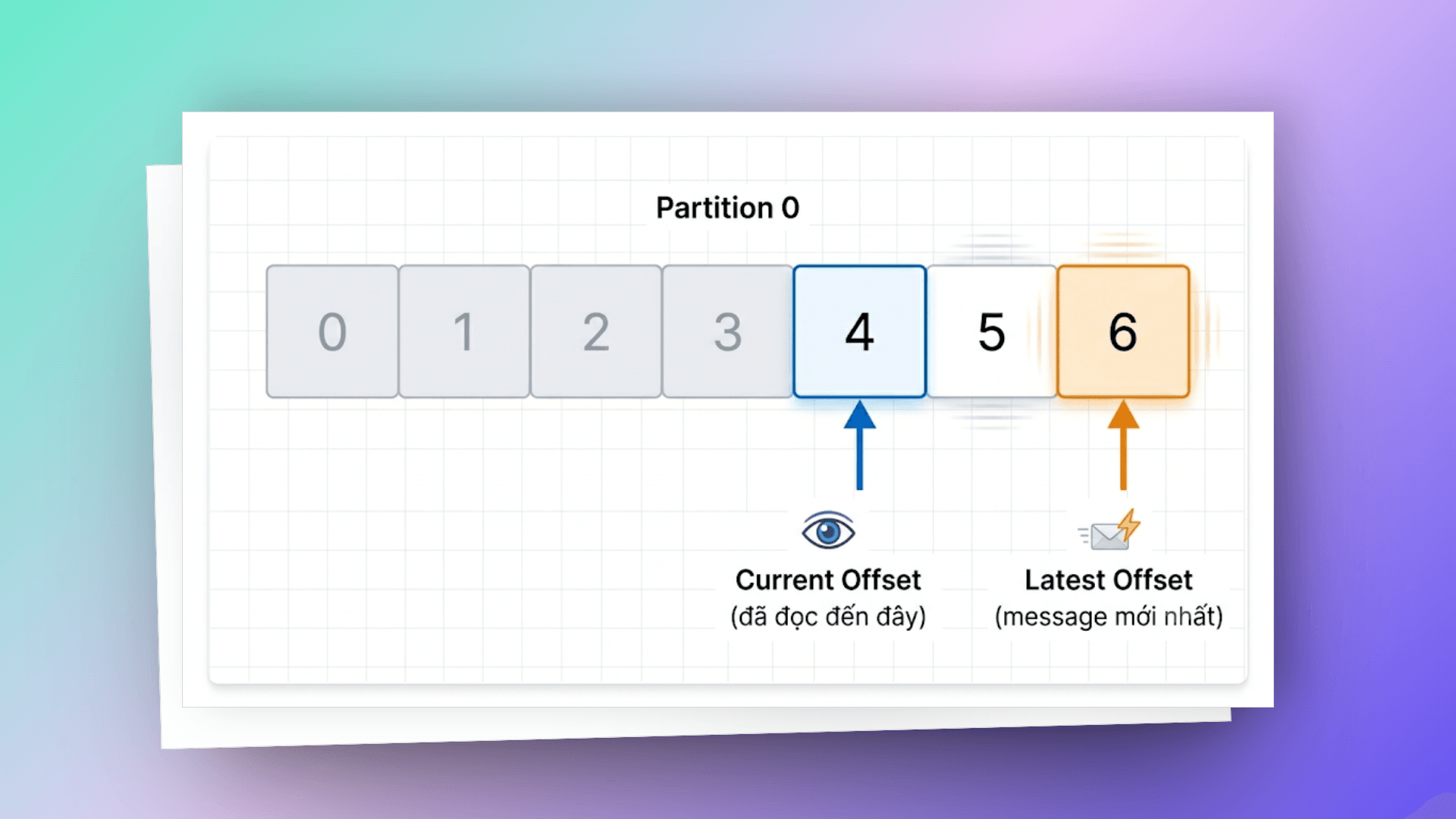
Consumer tự quản lý offset của mình. Điều này có nghĩa:
- Bạn có thể replay messages bằng cách reset offset về 0
- Nhiều consumer groups có thể đọc cùng topic ở các vị trí khác nhau
- Nếu consumer crash, nó resume từ last committed offset
# consumer group — scaling consumers
Đây là killer feature của Kafka. Một consumer group là một nhóm consumers cùng đọc một topic, trong đó mỗi partition chỉ được assign cho đúng 1 consumer trong group.
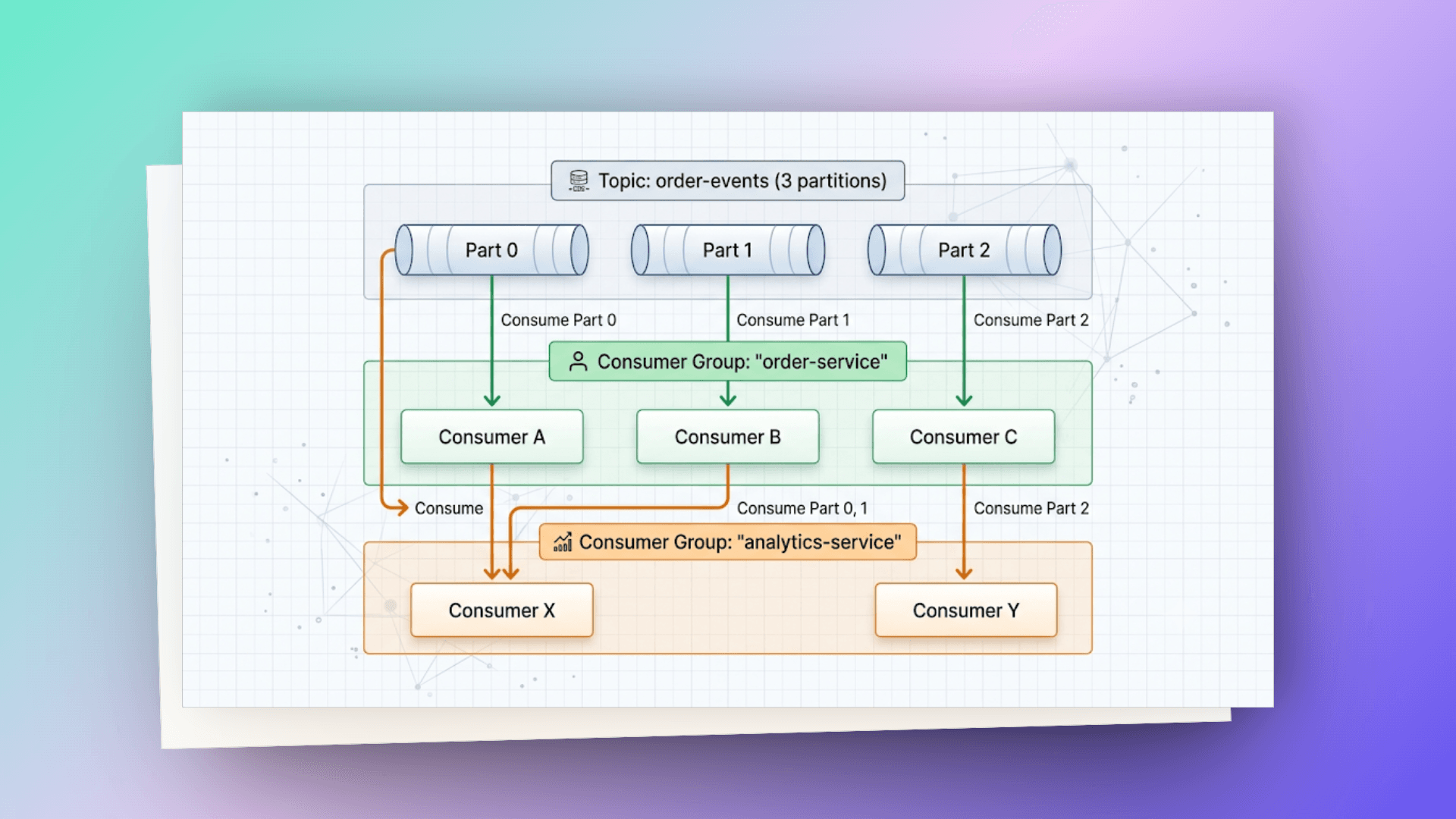
Quy tắc:
- Số consumers trong group ≤ số partitions → tối ưu
- Số consumers > số partitions → consumers thừa sẽ idle
- Thêm consumer vào group → Kafka tự động rebalance
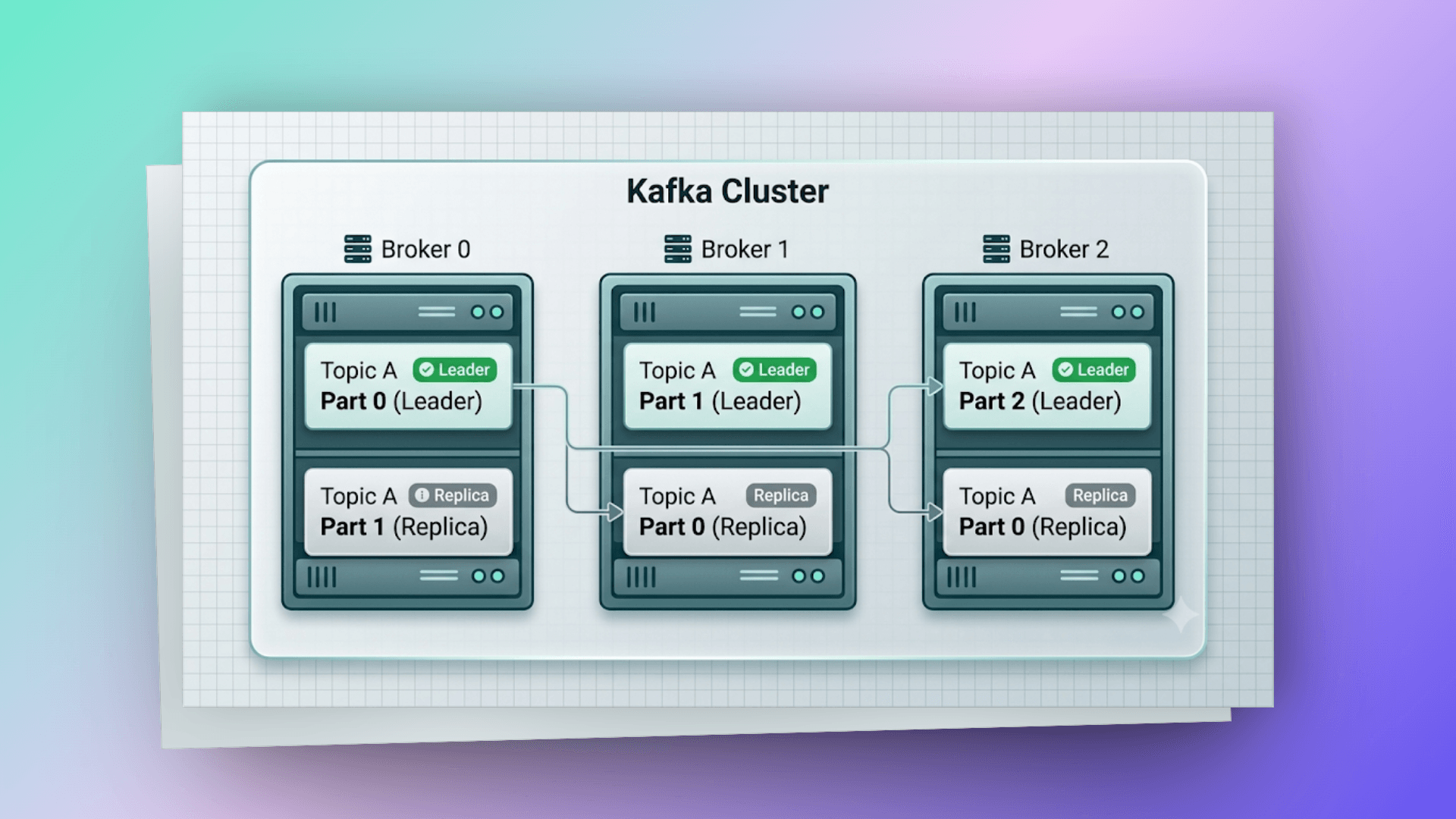
# replication — không mất dữ liệu
Mỗi partition có thể có nhiều replicas trên các brokers khác nhau:
- Leader replica: Nhận tất cả reads/writes
- Follower replicas: Sync data từ leader, sẵn sàng thay thế nếu leader down
Partition 0:
Broker 0: Leader ← Producer writes here, Consumer reads here
Broker 1: Follower ← Syncs from leader
Broker 2: Follower ← Syncs from leader
Nếu Broker 0 chết:
Broker 1: Leader (promoted) ← Tự động failover
Broker 2: Follower
ISR (In-Sync Replicas): Tập hợp các replicas đang sync kịp với leader. Config min.insync.replicas=2 đảm bảo ít nhất 2 replicas phải acknowledge trước khi message được coi là committed.
# kafka message anatomy

- Key: Quyết định message vào partition nào. Cùng key = cùng partition = đảm bảo ordering
- Value: Payload chính (thường là JSON hoặc Avro)
- Headers: Metadata bổ sung (correlation ID, trace ID, ...)
- Timestamp: Thời điểm message được tạo hoặc append
# hands-on: kafka với spring boot
Đủ lý thuyết rồi. Hãy code.
# project setup
<!-- pom.xml -->
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</dependency>
<!-- Test -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies># configuration — application.yml
spring:
kafka:
bootstrap-servers: localhost:9092
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.springframework.kafka.support.serializer.JsonSerializer
acks: all # Đợi tất cả ISR confirm → không mất data
retries: 3 # Retry khi gặp transient errors
properties:
enable.idempotence: true # Tránh duplicate messages khi retry
max.in.flight.requests.per.connection: 5
consumer:
group-id: order-service
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.springframework.kafka.support.serializer.JsonDeserializer
auto-offset-reset: earliest # Đọc từ đầu nếu chưa có committed offset
properties:
spring.json.trusted.packages: '*'
# Tạo topics tự động (chỉ dùng cho dev)
admin:
properties:
bootstrap.servers: localhost:9092⚠️ Production tip: Đừng bao giờ dùng
auto.create.topics.enable=trueở production. Luôn tạo topics explicitly với đúng số partitions và replication factor.
# domain model — order event
// OrderEvent.java
public class OrderEvent {
private String orderId;
private String userId;
private String product;
private BigDecimal amount;
private OrderStatus status;
private LocalDateTime timestamp;
public enum OrderStatus {
CREATED, CONFIRMED, SHIPPED, DELIVERED, CANCELLED
}
// Constructor mặc định cần cho deserialization
public OrderEvent() {}
public OrderEvent(String orderId, String userId, String product,
BigDecimal amount, OrderStatus status) {
this.orderId = orderId;
this.userId = userId;
this.product = product;
this.amount = amount;
this.status = status;
this.timestamp = LocalDateTime.now();
}
// Getters & Setters (hoặc dùng Lombok @Data)
public String getOrderId() { return orderId; }
public void setOrderId(String orderId) { this.orderId = orderId; }
public String getUserId() { return userId; }
public void setUserId(String userId) { this.userId = userId; }
public String getProduct() { return product; }
public void setProduct(String product) { this.product = product; }
public BigDecimal getAmount() { return amount; }
public void setAmount(BigDecimal amount) { this.amount = amount; }
public OrderStatus getStatus() { return status; }
public void setStatus(OrderStatus status) { this.status = status; }
public LocalDateTime getTimestamp() { return timestamp; }
public void setTimestamp(LocalDateTime timestamp) { this.timestamp = timestamp; }
@Override
public String toString() {
return "OrderEvent{orderId='%s', userId='%s', status=%s, amount=%s}"
.formatted(orderId, userId, status, amount);
}
}# topic configuration
// KafkaTopicConfig.java
@Configuration
public class KafkaTopicConfig {
@Bean
public NewTopic orderEventsTopic() {
return TopicBuilder.name("order-events")
.partitions(6) // 6 partitions cho parallel processing
.replicas(3) // 3 replicas cho fault tolerance
.config(TopicConfig.RETENTION_MS_CONFIG, "604800000") // 7 ngày
.config(TopicConfig.MIN_IN_SYNC_REPLICAS_CONFIG, "2")
.build();
}
@Bean
public NewTopic orderEventsDLT() {
// Dead Letter Topic — nơi chứa messages xử lý thất bại
return TopicBuilder.name("order-events.DLT")
.partitions(3)
.replicas(3)
.build();
}
}# producer — gửi events
// OrderEventProducer.java
@Service
@Slf4j
public class OrderEventProducer {
private final KafkaTemplate<String, OrderEvent> kafkaTemplate;
// Constructor injection — best practice
public OrderEventProducer(KafkaTemplate<String, OrderEvent> kafkaTemplate) {
this.kafkaTemplate = kafkaTemplate;
}
/**
* Gửi order event lên Kafka.
* Key = userId → tất cả events của cùng user vào cùng partition
* → đảm bảo ordering per user.
*/
public CompletableFuture<SendResult<String, OrderEvent>> publishOrderEvent(
OrderEvent event) {
log.info("Publishing event: {}", event);
return kafkaTemplate
.send("order-events", event.getUserId(), event)
.whenComplete((result, ex) -> {
if (ex == null) {
log.info("Event sent successfully: topic={}, partition={}, offset={}",
result.getRecordMetadata().topic(),
result.getRecordMetadata().partition(),
result.getRecordMetadata().offset());
} else {
log.error("Failed to send event: {}", event, ex);
// Ở đây bạn có thể: retry, gửi vào DLQ, alert, ...
}
});
}
/**
* Gửi event với custom headers — hữu ích cho tracing.
*/
public void publishWithHeaders(OrderEvent event, String correlationId) {
ProducerRecord<String, OrderEvent> record =
new ProducerRecord<>("order-events", event.getUserId(), event);
record.headers()
.add("correlationId", correlationId.getBytes(StandardCharsets.UTF_8))
.add("source", "order-service".getBytes(StandardCharsets.UTF_8));
kafkaTemplate.send(record);
}
}# consumer — nhận và xử lý events
// OrderEventConsumer.java
@Service
@Slf4j
public class OrderEventConsumer {
private final OrderService orderService;
public OrderEventConsumer(OrderService orderService) {
this.orderService = orderService;
}
/**
* Consumer cơ bản — đủ cho hầu hết use cases.
*
* concurrency = 3 → Spring tạo 3 consumer threads,
* mỗi thread xử lý 1 hoặc nhiều partitions.
*/
@KafkaListener(
topics = "order-events",
groupId = "order-service",
concurrency = "3"
)
public void handleOrderEvent(
@Payload OrderEvent event,
@Header(KafkaHeaders.RECEIVED_PARTITION) int partition,
@Header(KafkaHeaders.OFFSET) long offset,
@Header(KafkaHeaders.RECEIVED_TIMESTAMP) long timestamp) {
log.info("Received event: {} [partition={}, offset={}]",
event, partition, offset);
try {
orderService.processOrder(event);
} catch (Exception e) {
log.error("Error processing event at offset {}: {}",
offset, e.getMessage());
// Throw lại để Kafka retry hoặc gửi vào DLT
throw e;
}
}
/**
* Consumer với manual acknowledgment — khi bạn cần kiểm soát
* chính xác lúc nào offset được commit.
*/
@KafkaListener(
topics = "order-events",
groupId = "order-service-manual-ack",
containerFactory = "manualAckListenerFactory"
)
public void handleWithManualAck(
OrderEvent event,
Acknowledgment acknowledgment) {
try {
orderService.processOrder(event);
// Chỉ commit offset khi xử lý thành công
acknowledgment.acknowledge();
} catch (Exception e) {
// Không acknowledge → message sẽ được re-deliver
log.error("Processing failed, will retry: {}", e.getMessage());
}
}
/**
* Batch consumer — xử lý nhiều messages cùng lúc.
* Hiệu quả hơn khi cần bulk insert vào DB.
*/
@KafkaListener(
topics = "order-events",
groupId = "order-service-batch",
containerFactory = "batchListenerFactory"
)
public void handleBatch(List<OrderEvent> events) {
log.info("Received batch of {} events", events.size());
orderService.processBatch(events);
}
}# consumer factory configuration
// KafkaConsumerConfig.java
@Configuration
@EnableKafka
public class KafkaConsumerConfig {
@Value("${spring.kafka.bootstrap-servers}")
private String bootstrapServers;
@Bean
public ConsumerFactory<String, OrderEvent> consumerFactory() {
Map<String, Object> props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
JsonDeserializer.class);
props.put(JsonDeserializer.TRUSTED_PACKAGES, "*");
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
return new DefaultKafkaConsumerFactory<>(props);
}
/**
* Factory cho manual acknowledgment.
* AckMode.MANUAL_IMMEDIATE = commit ngay khi acknowledge() được gọi.
*/
@Bean
public ConcurrentKafkaListenerContainerFactory<String, OrderEvent>
manualAckListenerFactory() {
ConcurrentKafkaListenerContainerFactory<String, OrderEvent> factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
factory.getContainerProperties()
.setAckMode(ContainerProperties.AckMode.MANUAL_IMMEDIATE);
return factory;
}
/**
* Factory cho batch processing.
* max.poll.records = số messages tối đa mỗi lần poll.
*/
@Bean
public ConcurrentKafkaListenerContainerFactory<String, OrderEvent>
batchListenerFactory() {
ConcurrentKafkaListenerContainerFactory<String, OrderEvent> factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
factory.setBatchListener(true);
factory.getContainerProperties()
.setAckMode(ContainerProperties.AckMode.BATCH);
return factory;
}
}# error handling & dead letter topic
Đây là phần mà nhiều người bỏ qua, nhưng lại cực kỳ quan trọng ở production.
// KafkaErrorHandlingConfig.java
@Configuration
public class KafkaErrorHandlingConfig {
/**
* Retry 3 lần với backoff tăng dần, sau đó gửi vào Dead Letter Topic.
*
* Flow: message → retry 1 (1s) → retry 2 (2s) → retry 3 (4s) → DLT
*/
@Bean
public DefaultErrorHandler errorHandler(
KafkaOperations<String, OrderEvent> kafkaOperations) {
// Gửi message thất bại vào DLT
DeadLetterPublishingRecoverer recoverer =
new DeadLetterPublishingRecoverer(kafkaOperations,
(record, ex) -> new TopicPartition(
record.topic() + ".DLT",
record.partition()));
// Retry với exponential backoff
ExponentialBackOff backOff = new ExponentialBackOff(1000L, 2.0);
backOff.setMaxElapsedTime(15000L); // Max 15 giây tổng cộng
DefaultErrorHandler errorHandler =
new DefaultErrorHandler(recoverer, backOff);
// Không retry cho các lỗi không thể recover
errorHandler.addNotRetryableExceptions(
DeserializationException.class,
ClassCastException.class,
NullPointerException.class
);
return errorHandler;
}
}# rest controller — trigger events
// OrderController.java
@RestController
@RequestMapping("/api/orders")
public class OrderController {
private final OrderEventProducer producer;
public OrderController(OrderEventProducer producer) {
this.producer = producer;
}
@PostMapping
public ResponseEntity<Map<String, String>> createOrder(
@RequestBody CreateOrderRequest request) {
OrderEvent event = new OrderEvent(
UUID.randomUUID().toString(),
request.getUserId(),
request.getProduct(),
request.getAmount(),
OrderEvent.OrderStatus.CREATED
);
producer.publishOrderEvent(event);
return ResponseEntity.accepted()
.body(Map.of(
"orderId", event.getOrderId(),
"status", "ACCEPTED",
"message", "Order event published to Kafka"
));
}
}# patterns thực tế mà team tôi dùng hàng ngày
# pattern 1: transactional outbox
Vấn đề kinh điển: Bạn cần save vào DB VÀ publish event lên Kafka. Nếu một trong hai fail, data sẽ inconsistent.
❌ Cách sai:
1. Save to DB ← Thành công
2. Publish Kafka ← Fail → DB có data nhưng Kafka không có event
❌ Cách sai ngược:
1. Publish Kafka ← Thành công
2. Save to DB ← Fail → Kafka có event nhưng DB không có data
Giải pháp: Transactional Outbox Pattern
// OutboxEvent entity — lưu event vào cùng DB transaction với business data
@Entity
@Table(name = "outbox_events")
public class OutboxEvent {
@Id
private String id;
private String aggregateType; // "Order"
private String aggregateId; // orderId
private String eventType; // "OrderCreated"
@Column(columnDefinition = "TEXT")
private String payload; // JSON serialized event
private LocalDateTime createdAt;
private boolean published;
// constructors, getters, setters...
}
// Service — save business data + outbox event trong cùng 1 transaction
@Service
@Transactional
public class OrderService {
private final OrderRepository orderRepository;
private final OutboxRepository outboxRepository;
private final ObjectMapper objectMapper;
public Order createOrder(CreateOrderRequest request) {
// 1. Save business data
Order order = new Order(request);
orderRepository.save(order);
// 2. Save outbox event (cùng transaction)
OutboxEvent outboxEvent = new OutboxEvent();
outboxEvent.setId(UUID.randomUUID().toString());
outboxEvent.setAggregateType("Order");
outboxEvent.setAggregateId(order.getId());
outboxEvent.setEventType("OrderCreated");
outboxEvent.setPayload(objectMapper.writeValueAsString(order));
outboxEvent.setCreatedAt(LocalDateTime.now());
outboxEvent.setPublished(false);
outboxRepository.save(outboxEvent);
return order;
// Cả hai save cùng commit hoặc cùng rollback
}
}
// Scheduler — poll outbox table và publish lên Kafka
@Component
@Slf4j
public class OutboxPublisher {
private final OutboxRepository outboxRepository;
private final KafkaTemplate<String, String> kafkaTemplate;
@Scheduled(fixedDelay = 1000) // Poll mỗi giây
@Transactional
public void publishPendingEvents() {
List<OutboxEvent> events =
outboxRepository.findByPublishedFalseOrderByCreatedAtAsc();
for (OutboxEvent event : events) {
try {
kafkaTemplate.send(
event.getAggregateType().toLowerCase() + "-events",
event.getAggregateId(),
event.getPayload()
).get(); // Blocking wait để đảm bảo gửi thành công
event.setPublished(true);
outboxRepository.save(event);
} catch (Exception e) {
log.error("Failed to publish outbox event: {}", event.getId(), e);
break; // Dừng lại, retry ở lần poll tiếp theo
}
}
}
}# pattern 2: event sourcing với Kafka
Thay vì lưu state hiện tại, bạn lưu tất cả events đã xảy ra. State được rebuild bằng cách replay events.
// Các events cho Order aggregate
public sealed interface OrderDomainEvent {
String orderId();
record OrderCreated(String orderId, String userId,
String product, BigDecimal amount) implements OrderDomainEvent {}
record OrderConfirmed(String orderId, LocalDateTime confirmedAt)
implements OrderDomainEvent {}
record OrderShipped(String orderId, String trackingNumber)
implements OrderDomainEvent {}
record OrderCancelled(String orderId, String reason)
implements OrderDomainEvent {}
}
// Rebuild state từ events
public class OrderAggregate {
private String orderId;
private String userId;
private OrderStatus status;
private BigDecimal amount;
private String trackingNumber;
public static OrderAggregate replayEvents(List<OrderDomainEvent> events) {
OrderAggregate aggregate = new OrderAggregate();
events.forEach(aggregate::apply);
return aggregate;
}
private void apply(OrderDomainEvent event) {
switch (event) {
case OrderDomainEvent.OrderCreated e -> {
this.orderId = e.orderId();
this.userId = e.userId();
this.amount = e.amount();
this.status = OrderStatus.CREATED;
}
case OrderDomainEvent.OrderConfirmed e -> {
this.status = OrderStatus.CONFIRMED;
}
case OrderDomainEvent.OrderShipped e -> {
this.status = OrderStatus.SHIPPED;
this.trackingNumber = e.trackingNumber();
}
case OrderDomainEvent.OrderCancelled e -> {
this.status = OrderStatus.CANCELLED;
}
}
}
}# pattern 3: saga pattern — distributed transactions
Khi một business operation span qua nhiều services, bạn cần Saga pattern.
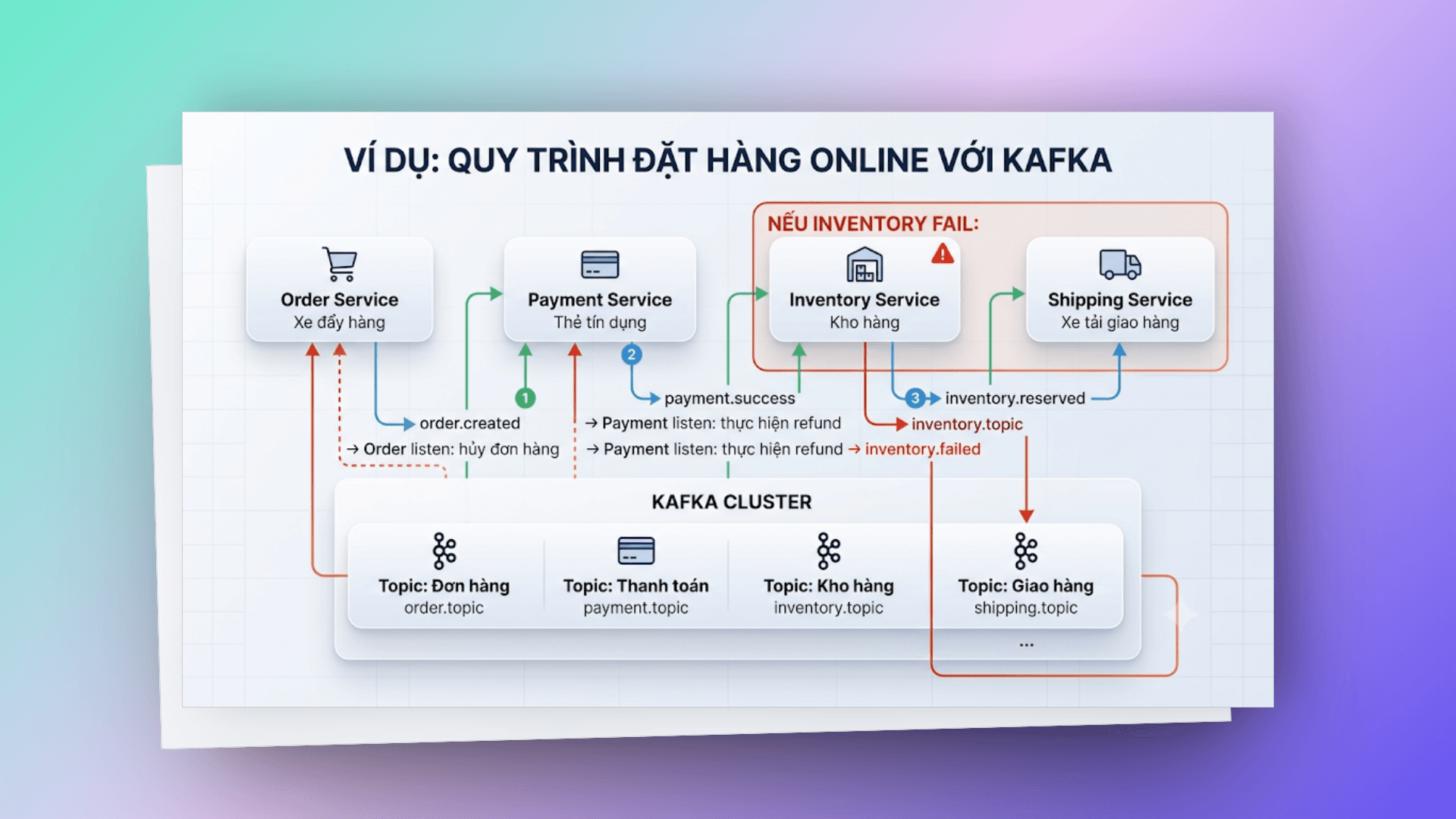
Triển khai code với Java:
// Orchestrator-based Saga
@Service
@Slf4j
public class OrderSagaOrchestrator {
private final KafkaTemplate<String, SagaEvent> kafkaTemplate;
@KafkaListener(topics = "saga-order-reply", groupId = "saga-orchestrator")
public void handleSagaReply(SagaEvent event) {
switch (event.getStep()) {
case "PAYMENT_SUCCESS" -> {
log.info("Payment successful, reserving inventory...");
kafkaTemplate.send("saga-inventory-request",
event.getOrderId(),
SagaEvent.of(event.getOrderId(), "RESERVE_INVENTORY"));
}
case "INVENTORY_RESERVED" -> {
log.info("Inventory reserved, initiating shipping...");
kafkaTemplate.send("saga-shipping-request",
event.getOrderId(),
SagaEvent.of(event.getOrderId(), "CREATE_SHIPMENT"));
}
case "PAYMENT_FAILED" -> {
log.warn("Payment failed, cancelling order...");
kafkaTemplate.send("saga-order-request",
event.getOrderId(),
SagaEvent.of(event.getOrderId(), "CANCEL_ORDER"));
}
case "INVENTORY_FAILED" -> {
log.warn("Inventory failed, refunding payment...");
kafkaTemplate.send("saga-payment-request",
event.getOrderId(),
SagaEvent.of(event.getOrderId(), "REFUND_PAYMENT"));
}
}
}
}# kafka streams — processing trong kafka
Kafka Streams là một library cho phép bạn xử lý data trực tiếp trong Kafka, không cần external processing framework.
// Real-time order analytics với Kafka Streams
@Configuration
@EnableKafkaStreams
public class OrderAnalyticsStream {
@Bean
public KStream<String, OrderEvent> orderAnalytics(
StreamsBuilder streamsBuilder) {
// Đọc từ topic
KStream<String, OrderEvent> orderStream = streamsBuilder
.stream("order-events",
Consumed.with(Serdes.String(), orderEventSerde()));
// 1. Filter: chỉ lấy orders đã confirmed
KStream<String, OrderEvent> confirmedOrders = orderStream
.filter((key, event) ->
event.getStatus() == OrderEvent.OrderStatus.CONFIRMED);
// 2. Tính tổng revenue theo user (windowed aggregation)
KTable<Windowed<String>, BigDecimal> revenuePerUser = confirmedOrders
.groupByKey()
.windowedBy(TimeWindows.ofSizeWithNoGrace(Duration.ofHours(1)))
.aggregate(
() -> BigDecimal.ZERO,
(userId, event, total) -> total.add(event.getAmount()),
Materialized.with(Serdes.String(), bigDecimalSerde())
);
// 3. Detect high-value orders → gửi alert
orderStream
.filter((key, event) ->
event.getAmount().compareTo(new BigDecimal("10000")) > 0)
.to("high-value-order-alerts",
Produced.with(Serdes.String(), orderEventSerde()));
// 4. Branch: phân loại orders theo status
Map<String, KStream<String, OrderEvent>> branches = orderStream
.split(Named.as("order-"))
.branch((key, event) ->
event.getStatus() == OrderEvent.OrderStatus.CANCELLED,
Branched.as("cancelled"))
.branch((key, event) ->
event.getStatus() == OrderEvent.OrderStatus.SHIPPED,
Branched.as("shipped"))
.defaultBranch(Branched.as("other"));
branches.get("order-cancelled")
.to("cancelled-orders");
return orderStream;
}
}# production checklist — những bài học xương máu
# monitoring — metrics PHẢI theo dõi
# Prometheus metrics quan trọng nhất:
# Consumer lag — số messages chưa được xử lý
# Nếu lag tăng liên tục → consumer không kịp xử lý
kafka_consumer_group_lag{group="order-service", topic="order-events"}
# Producer request latency
kafka_producer_request_latency_avg
# Consumer poll rate
kafka_consumer_poll_rate
# Under-replicated partitions — DẤU HIỆU NGUY HIỂM
kafka_server_replica_manager_under_replicated_partitions// Spring Boot Actuator + Micrometer cho Kafka metrics
@Configuration
public class KafkaMetricsConfig {
@Bean
public MicrometerConsumerListener<String, OrderEvent> consumerListener(
MeterRegistry registry) {
return new MicrometerConsumerListener<>(registry);
}
@Bean
public MicrometerProducerListener<String, OrderEvent> producerListener(
MeterRegistry registry) {
return new MicrometerProducerListener<>(registry);
}
}# idempotent consumer — xử lý duplicate messages
Kafka đảm bảo at-least-once delivery. Nghĩa là message có thể được deliver nhiều lần. Consumer của bạn PHẢI idempotent.
@Service
public class IdempotentOrderConsumer {
private final ProcessedEventRepository processedEventRepo;
private final OrderService orderService;
@KafkaListener(topics = "order-events", groupId = "order-service")
@Transactional
public void handle(OrderEvent event,
@Header(KafkaHeaders.RECEIVED_PARTITION) int partition,
@Header(KafkaHeaders.OFFSET) long offset) {
// Tạo unique ID từ partition + offset (hoặc dùng event ID)
String eventId = "order-events-%d-%d".formatted(partition, offset);
// Check đã xử lý chưa
if (processedEventRepo.existsById(eventId)) {
log.warn("Duplicate event detected, skipping: {}", eventId);
return;
}
// Xử lý business logic
orderService.processOrder(event);
// Đánh dấu đã xử lý (cùng transaction với business logic)
processedEventRepo.save(new ProcessedEvent(eventId, LocalDateTime.now()));
}
}# performance tuning
# Producer tuning
spring:
kafka:
producer:
# Batch messages trước khi gửi → tăng throughput
batch-size: 32768 # 32KB
# Đợi tối đa 5ms để gom batch
properties:
linger.ms: 5
# Compression — giảm network bandwidth
compression.type: lz4 # lz4 = fast, snappy = balanced, zstd = best ratio
# Buffer memory cho producer
buffer.memory: 67108864 # 64MB
consumer:
# Số messages tối đa mỗi lần poll
properties:
max.poll.records: 500
# Thời gian tối đa giữa 2 lần poll
# Nếu vượt quá → consumer bị coi là dead → rebalance
max.poll.interval.ms: 300000 # 5 phút
# Fetch size
fetch.min.bytes: 1024
fetch.max.wait.ms: 500Docker Compose cho Local Development
# docker-compose.yml
version: '3.8'
services:
zookeeper:
image: confluentinc/cp-zookeeper:7.5.0
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
kafka:
image: confluentinc/cp-kafka:7.5.0
depends_on:
- zookeeper
ports:
- '9092:9092'
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://localhost:9092
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_AUTO_CREATE_TOPICS_ENABLE: 'true'
# UI để visualize Kafka — rất hữu ích khi debug
kafka-ui:
image: provectuslabs/kafka-ui:latest
ports:
- '8080:8080'
environment:
KAFKA_CLUSTERS_0_NAME: local
KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS: kafka:9092💡 Tip: Dùng KRaft mode (Kafka 3.3+) để bỏ Zookeeper dependency. Đơn giản hơn nhiều cho local dev.
# common pitfalls — những lỗi từng mắc phải
# consumer rebalance storm
Triệu chứng: Consumer liên tục join/leave group, không xử lý được message nào.
Nguyên nhân: max.poll.interval.ms quá nhỏ so với thời gian xử lý.
// Sai: xử lý mất 10 phút nhưng max.poll.interval chỉ 5 phút
@KafkaListener(topics = "heavy-processing")
public void handle(Event event) {
heavyProcessing(event); // Mất 10 phút
// → Consumer bị kick khỏi group → rebalance → message bị re-deliver
}
// Đúng: tăng max.poll.interval HOẶC giảm max.poll.records
// Hoặc tốt hơn: offload heavy processing sang thread pool
@KafkaListener(topics = "heavy-processing",
properties = {
"max.poll.interval.ms=600000", // 10 phút
"max.poll.records=10" // Ít records hơn mỗi lần poll
})
public void handle(Event event) {
heavyProcessing(event);
}# message ordering bị phá vỡ
// Sai: retries có thể làm đảo thứ tự messages
// Message A gửi → fail → retry
// Message B gửi → success
// Message A retry → success
// Kết quả: B trước A → sai thứ tự!
// Đúng: bật idempotence (tự động giới hạn in-flight requests)
spring.kafka.producer.properties.enable.idempotence=true
// Hoặc set max.in.flight.requests.per.connection=1 (nhưng giảm throughput)# poison pill message
Một message bị corrupt hoặc không deserialize được sẽ block consumer mãi mãi.
// ✅ Giải pháp: ErrorHandlingDeserializer
spring:
kafka:
consumer:
key-deserializer: org.springframework.kafka.support.serializer.ErrorHandlingDeserializer
value-deserializer: org.springframework.kafka.support.serializer.ErrorHandlingDeserializer
properties:
spring.deserializer.key.delegate.class: org.apache.kafka.common.serialization.StringDeserializer
spring.deserializer.value.delegate.class: org.springframework.kafka.support.serializer.JsonDeserializer# không set consumer group id
// Mỗi lần restart, consumer tạo group mới → đọc lại từ đầu
@KafkaListener(topics = "events") // Không có groupId
// Luôn set groupId cố định
@KafkaListener(topics = "events", groupId = "my-service")# topic partition count không thay đổi được (giảm)
Bạn tạo topic với 3 partitions.
Traffic tăng → bạn tăng lên 12 partitions. OK.
Traffic giảm → bạn muốn giảm về 6 partitions. KHÔNG ĐƯỢC.
→ Plan ahead. Bắt đầu với số partitions hợp lý.
→ Nếu cần giảm: tạo topic mới, migrate data.
# schema evolution — khi event thay đổi
Đây là vấn đề mà bạn SẼ gặp khi hệ thống phát triển. Event schema thay đổi theo thời gian, nhưng consumers cũ vẫn cần đọc được.
// Version 1: OrderEvent ban đầu
{
"orderId": "abc-123",
"amount": 99.99
}
// Version 2: Thêm field mới (backward compatible ✅)
{
"orderId": "abc-123",
"amount": 99.99,
"currency": "USD" // Mới — consumer cũ ignore field này
}
// Version 3: Đổi tên field (BREAKING CHANGE ❌)
{
"orderId": "abc-123",
"totalAmount": 99.99 // Consumer cũ tìm "amount" → null
}Best practices:
- Chỉ thêm fields mới (có default value)
- Không xóa hoặc rename fields
- Dùng Apache Avro + Schema Registry cho production
// Avro schema evolution với Spring
@Configuration
public class AvroConfig {
@Bean
public ProducerFactory<String, GenericRecord> avroProducerFactory() {
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
StringSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
KafkaAvroSerializer.class);
props.put("schema.registry.url", "http://localhost:8081");
return new DefaultKafkaProducerFactory<>(props);
}
}# khi nào KHÔNG nên dùng Kafka?
Kafka không phải silver bullet. Đừng dùng Kafka khi:
- Simple request-response: REST/gRPC đơn giản hơn nhiều
- Ít data, ít traffic: Overhead vận hành Kafka không đáng
- Cần exactly-once delivery đơn giản: Kafka hỗ trợ nhưng phức tạp
- Real-time chat/notifications: WebSocket + Redis Pub/Sub phù hợp hơn
- Batch processing thuần túy: Spark/Flink có thể đọc trực tiếp từ storage
Dùng Kafka khi:
- Nhiều services cần đọc cùng một stream of events
- Cần replay/audit trail
- High throughput (>10K msg/s)
- Event-driven architecture
- Decoupling services trong microservices
# kết luận
Kafka Cheat Sheet:
Topic = Logical channel cho messages
Partition = Unit of parallelism & ordering
Offset = Position của message trong partition
Broker = Kafka server instance
Consumer Group = Nhóm consumers chia nhau partitions
ISR = In-Sync Replicas — đảm bảo durability
Producer: acks=all + idempotence=true → không mất data
Consumer: idempotent processing + DLT → không sợ failures
Partition key: cùng key = cùng partition = ordering guarantee
Kafka là một công cụ mạnh mẽ, nhưng đi kèm với complexity. Hãy bắt đầu đơn giản — một producer, một consumer, một topic. Hiểu rõ từng concept trước khi scale lên.
Và nhớ: Kafka không phải message queue. Kafka là distributed commit log. Khi bạn thực sự hiểu điều này, mọi thứ khác sẽ make sense.
Chỉ là những ghi chép cá nhân với hy vọng mang lại chút giá trị. Nếu thấy hữu ích, đừng ngại chia sẻ cho bạn bè & đồng nghiệp nhé!
Happy coding 😎 👍🏻 🚀 🔥.
On this page
- # kafka là gì?
- # why not RabbitMQ or Redis Pub/Sub?
- # kiến trúc kafka
- # broker — Trái tim của Kafka
- # topic — kênh dữ liệu
- # partition — Chìa khóa của Scalability
- # offset — bookmark của consumer
- # consumer group — scaling consumers
- # replication — không mất dữ liệu
- # kafka message anatomy
- # hands-on: kafka với spring boot
- # project setup
- # configuration — application.yml
- # domain model — order event
- # topic configuration
- # producer — gửi events
- # consumer — nhận và xử lý events
- # consumer factory configuration
- # error handling & dead letter topic
- # rest controller — trigger events
- # patterns thực tế mà team tôi dùng hàng ngày
- # pattern 1: transactional outbox
- # pattern 2: event sourcing với Kafka
- # pattern 3: saga pattern — distributed transactions
- # kafka streams — processing trong kafka
- # production checklist — những bài học xương máu
- # monitoring — metrics PHẢI theo dõi
- # idempotent consumer — xử lý duplicate messages
- # performance tuning
- Docker Compose cho Local Development
- # common pitfalls — những lỗi từng mắc phải
- # consumer rebalance storm
- # message ordering bị phá vỡ
- # poison pill message
- # không set consumer group id
- # topic partition count không thay đổi được (giảm)
- # schema evolution — khi event thay đổi
- # khi nào KHÔNG nên dùng Kafka?
- # kết luận